Einfache Fragen 01¶
Frage 1: Daten, Informationen und Wissen¶
- Daten: Zeichen oder Symbole ohne Bedeutung (Rohmaterial, z. B. „10“).
- Informationen: Daten in einem Kontext (z. B. „10 Grad Celsius“). Sie geben den Daten einen Sinn.
- Wissen: Die Vernetzung von Informationen mit Erfahrung oder Logik (z. B. „Bei 10 Grad brauche ich eine Jacke“).
Frage 2: Relationale vs. NoSQL-Datenbanken¶
- Relationale Datenbanken: Speichern Daten in festen Tabellen mit Zeilen und Spalten. Sie nutzen ein starres Schema und SQL (z. B. MySQL, PostgreSQL).
- NoSQL-Datenbanken: Speichern Daten flexibel, oft als Dokumente (JSON/BSON). Sie haben kein starres Schema und lassen sich leichter auf viele Server verteilen (z. B. MongoDB).
Frage 3: Datenqualität und vier Aspekte¶
Definition: Datenqualität beschreibt, wie gut Daten für ihren vorgesehenen Zweck geeignet sind.
Vier wichtige Aspekte:
- Korrektheit: Die Daten müssen wahrheitsgetreu sein.
- Vollständigkeit: Alle benötigten Werte müssen vorhanden sein.
- Konsistenz: Die Daten dürfen sich nicht widersprechen (z. B. gleiches Geburtsdatum in allen Tabellen).
- Aktualität: Die Daten müssen auf dem neuesten Stand sein.
Frage 4: Rolle und Berechtigungen des IT-Administrators¶
- Rolle: Er ist für die Infrastruktur verantwortlich. Er sorgt dafür, dass der Server läuft, sicher ist und Backups erstellt werden. Er pflegt nicht die Inhalte (Filme), sondern das System.
- Berechtigungen:
- User Management: Er darf Accounts erstellen und Passwörter vergeben.
- Lese- und Schreibrechte: Er hat vollen Zugriff auf alle Datenbanken (Root-Rechte).
- Wartung: Er darf Datenbanken löschen, Indizes zur Beschleunigung anlegen und Wiederherstellungen (
mongorestore) durchführen.
Mittlere Fragen 01¶
Frage 5: Konzept der Abstraktion¶
- Konzept: Abstraktion bedeutet, Komplexität zu reduzieren, indem man unwichtige Details ausblendet und sich auf die wesentlichen Merkmale konzentriert.
- In der Datenverarbeitung: Man nutzt Schichten (z. B. das 3-Ebenen-Modell), damit ein Nutzer mit Daten arbeiten kann (z. B. in einer App), ohne wissen zu müssen, wie diese technisch auf der Festplatte gespeichert sind.
Frage 6: Bedeutung von Redundanz¶
- Bedeutung: Redundanz ist das mehrfache Vorhandensein derselben Daten in einer Datenbank.
- Probleme:
- Anomalien: Wenn Daten an einer Stelle geändert werden, an einer anderen aber alt bleiben (Inkonsistenz).
- Speicherplatzverschwendung: Gleiche Info belegt unnötig Platz.
- Fehleranfälligkeit: Erhöhter Aufwand bei der Datenpflege.
Frage 7: Normalisierung (Relat. Datenbanken)¶
- Erklärung: Normalisierung ist das Aufteilen von Daten in mehrere Tabellen, um Redundanzen zu minimieren und logische Datenstrukturen zu schaffen.
- Die drei Normalformen:
- 1. NF (Atomarität): Jeder Tabelleneintrag muss atomar sein (nur ein Wert pro Zelle, keine Listen).
- 2. NF: Die 1. NF muss erfüllt sein und jedes Nicht-Schlüsselattribut muss voll vom Primärschlüssel abhängen.
- 3. NF: Die 2. NF muss erfüllt sein und es dürfen keine transitiven Abhängigkeiten bestehen (Nicht-Schlüsselattribute dürfen nicht voneinander abhängen).
Frage 8: Rolle und Berechtigungen des Verwaltungspersonals¶
- Rolle: Sie sind die Anwender oder Inhaltsverwalter. Sie pflegen die Datenbestände (z. B. neue Filme anlegen, Schauspieler korrigieren) und nutzen die Datenbank für das Tagesgeschäft.
- Berechtigungen:
- Datenpflege (CRUD): Erstellen, Lesen, Aktualisieren und (eingeschränkt) Löschen von Datensätzen.
- Keine Systemrechte: Sie dürfen keine Datenbanken löschen, keine Indizes erstellen und keine anderen Benutzer verwalten.
- Berichtswesen: Sie dürfen Abfragen (Queries) ausführen, um Listen oder Statistiken zu erstellen.
Schwere Fragen 01¶
Frage 9: NewSQL vs. Relationale vs. NoSQL-Datenbanken¶
| Datenbanktyp | Beschreibung | Hauptmerkmale |
|---|---|---|
| Relational (SQL) | Klassische Tabellenstruktur (z. B. MySQL). | ACID-Garantie (Sicherheit), starres Schema, schwer horizontal skalierbar. |
| NoSQL | Flexible Dokumente oder Key-Value (z. B. MongoDB). | Hohe Skalierbarkeit, flexibles Schema, verzichtet oft auf volle ACID-Strenge. |
| NewSQL | Moderne Kombination beider Welten (z. B. CockroachDB). | Bietet die Skalierbarkeit von NoSQL, behält aber die ACID-Garantien und SQL-Schnittstellen bei. |
Frage 10: Rollenkonzept (RBAC) in der Datensicherheit¶
- Konzept: Berechtigungen werden nicht einzelnen Benutzern, sondern Rollen (z. B. „Admin“, „Editor“, „Viewer“) zugewiesen. Benutzer erhalten dann eine dieser Rollen.
- Bedeutung für Sicherheit:
- Principle of Least Privilege: Benutzer erhalten nur die Rechte, die sie für ihre Arbeit zwingend benötigen.
- Fehlerminimierung: Verhindert versehentliches Löschen oder unbefugte Einsicht in sensible Daten durch klare Trennung.
- Verwaltbarkeit: Rechteänderungen erfolgen zentral für eine Rolle, statt für jeden Nutzer einzeln.
Frage 11: Datensicherheitskonzepte und Konsequenzen¶
- Bedeutung: Schutz der CIA-Ziele (Confidentiality/Vertraulichkeit, Integrity/Integrität, Availability/Verfügbarkeit) von Unternehmensdaten.
- Konsequenzen bei Nichteinhaltung:
- Rechtlich: Hohe Bußgelder (z. B. durch die DSGVO).
- Finanziell: Kosten durch Betriebsunterbrechungen oder Lösegelderpressungen.
- Reputation: Vertrauensverlust bei Kunden und Partnern.
- Operativ: Endgültiger Verlust von geschäftskritischen Daten.
Frage 12: Rollenspiel im Fitnesscenter (Rollen & Berechtigungen)¶
- Vorgehen: Teilnehmer schlüpfen in Rollen wie Rezeptionist, Trainer und Geschäftsführer.
- Nutzen: * Verdeutlicht, warum ein Trainer zwar Trainingspläne ändern darf, aber keinen Zugriff auf Kontodaten (Rezeption/Buchhaltung) haben sollte.
- Zeigt praxisnah, welche Sicherheitsrisiken entstehen, wenn Berechtigungen zu weit gefasst sind (z. B. Rezeptionist löscht versehentlich alle Verträge).
- Fördert das Verständnis für notwendige Zugriffsbeschränkungen im Arbeitsalltag.
Einfache Fragen 02¶
Frage 1: Hauptunterschiede SQL vs. NoSQL¶
| Merkmal | Relationale Datenbanken (SQL) | NoSQL-Datenbanken |
|---|---|---|
| Datenstruktur | Tabellen (Zeilen und Spalten). | Dokumente, Key-Value, Graphen oder Spalten. |
| Schema | Starr/Vordefiniert (Schema-first). | Flexibel/Dynamisch (Schema-on-read). |
| Skalierbarkeit | Vertikal (stärkerer Server). | Horizontal (mehrere Server/Cluster). |
| Transaktionen | Fokus auf ACID (starke Konsistenz). | Fokus auf BASE (eventuelle Konsistenz). |
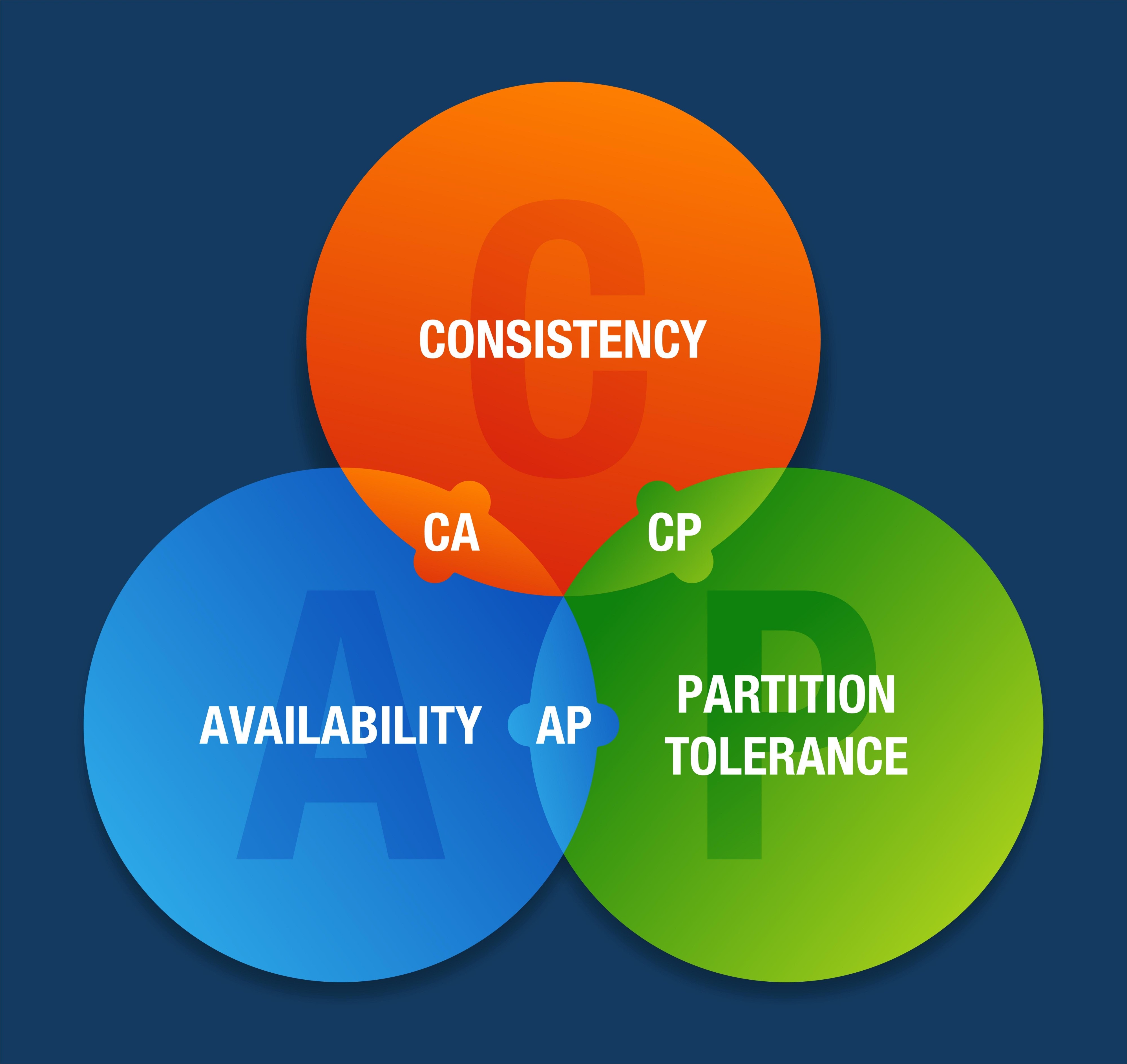
Frage 2: Das CAP-Theorem¶
Das Theorem besagt, dass in einem verteilten System nur zwei der folgenden drei Eigenschaften gleichzeitig garantiert werden können:
- Consistency (Konsistenz): Alle Knoten sehen zur gleichen Zeit dieselben Daten.
- Availability (Verfügbarkeit): Jede Anfrage erhält eine Antwort (Erfolg oder Fehler).
- Partition Tolerance (Partitionstoleranz): Das System funktioniert weiter, auch wenn die Kommunikation zwischen Knoten unterbrochen ist.
Wichtig: Da Partitionstoleranz in verteilten Systemen zwingend ist, muss man sich meist zwischen Konsistenz (CP) und Verfügbarkeit (AP) entscheiden.
Frage 3: Die vier Haupttypen von NoSQL-Datenbanken¶
- Dokumentenorientiert: Daten werden in Dokumenten gespeichert (z. B. JSON/BSON). Beispiel: MongoDB.
- Key-Value (Schlüssel-Wert): Daten werden als einfache Paare gespeichert. Beispiel: Redis.
- Spaltenorientiert (Column-Family): Daten werden in Spalten statt Zeilen gespeichert. Beispiel: Cassandra.
- Graphdatenbanken: Fokus auf Beziehungen zwischen Datenknoten. Beispiel: Neo4j.
Frage 4: Vorteile von JSON gegenüber XML¶
- Geringerer Overhead: JSON ist weniger „geschwätzig“, da es keine schließenden Tags benötigt. Dateien sind kleiner.
- Schnelleres Parsing: JSON kann von Browsern und Servern wesentlich schneller verarbeitet werden.
- Native Hierarchie: JSON bildet Datenstrukturen (Arrays, Objekte) ab, die direkt in modernen Programmiersprachen (besonders JavaScript) verwendet werden können.
- Lesbarkeit: JSON ist für Menschen oft einfacher und sauberer zu lesen als verschachtelte XML-Strukturen.
Mittlere Fragen 02¶
Frage 5: Vorteile und Herausforderungen bei NoSQL in grossen Anwendungen¶
- Vorteile:
- Horizontale Skalierbarkeit: Einfaches Hinzufügen von Servern (Sharding) statt nur Aufrüsten eines einzelnen Servers.
- Flexibles Schema: Datenstrukturen können sich ohne Downtime ändern.
-
Performance: Optimiert für hohe Schreibgeschwindigkeiten und spezifische Datenmodelle.
-
Herausforderungen:
- Datenkonsistenz: Oft nur "Eventual Consistency", was die Anwendungslogik komplexer macht.
- Fehlende Standards: Jede NoSQL-Datenbank hat eine eigene Abfragesprache (kein einheitliches SQL).
- Eingeschränkte Joins: Verknüpfungen müssen oft mühsam in der Applikation statt in der Datenbank gelöst werden.
Frage 6: Datenmodellierung in dokumentenbasierten Datenbanken (MongoDB)¶
Die Modellierung folgt zwei Hauptstrategien:
- Embedding (Einbetten): Zusammengehörige Daten werden in einem einzigen Dokument gespeichert (verschachtelt). Das ermöglicht sehr schnelle Lesezugriffe, da alle Infos mit einer Abfrage da sind.
- Referencing (Referenzieren): Dokumente speichern nur die IDs anderer Dokumente (ähnlich wie Fremdschlüssel). Das verhindert Datenredundanz und wird bei grossen Datenmengen oder komplexen Viele-zu-Viele-Beziehungen genutzt.
Frage 7: Eventual Consistency¶
- Definition: Ein Konsistenzmodell, bei dem garantiert wird, dass – sofern keine neuen Schreibvorgänge erfolgen – irgendwann (eventuell) alle Kopien der Daten auf allen Knoten denselben Wert haben.
- Hintergrund: Um hohe Verfügbarkeit und Geschwindigkeit zu erreichen, akzeptiert das System, dass Nutzer für eine sehr kurze Zeitspanne leicht veraltete Daten sehen könnten, während die Aktualisierung im Hintergrund im Cluster verteilt wird.
Frage 8: CP-, AP- und CA-Datenbanken (CAP-Theorem)¶
Da bei Netzwerkproblemen (Partitionen) immer die Partitionstoleranz (P) gewählt werden muss, gibt es in verteilten Systemen meist nur zwei Wege:
- CP (Consistency / Partition Tolerance): Das System wählt Datenkonsistenz. Bei einem Netzwerkfehler antwortet das System lieber mit einem Fehler, als falsche/veraltete Daten zu liefern (z. B. MongoDB).
- AP (Availability / Partition Tolerance): Das System wählt Verfügbarkeit. Es antwortet immer, auch wenn die Daten aufgrund des Netzwerkfehlers auf diesem Knoten eventuell noch veraltet sind (z. B. Cassandra).
- CA (Consistency / Availability): Konsistenz und Verfügbarkeit gleichzeitig. Dies ist nur in Systemen möglich, die nicht verteilt sind (z. B. eine lokale relationale Datenbank ohne Cluster-Verbund).
Schwere Fragen 02¶
Frage 9: Vor- und Nachteile der Denormalisierung in NoSQL¶
- Vorteile:
- Performance: Enorm schnelle Lesezugriffe, da keine teuren Verknüpfungen (Joins) über mehrere Tabellen nötig sind.
-
Skalierbarkeit: Daten sind in sich abgeschlossen (Self-contained) und lassen sich einfacher auf verschiedene Server verteilen.
-
Nachteile:
- Datenredundanz: Informationen werden mehrfach gespeichert, was den Speicherbedarf erhöht.
- Update-Komplexität: Bei Änderungen müssen alle Kopien des Datensatzes aktualisiert werden, was das Risiko für Inkonsistenzen erhöht.
Frage 10: Datenintegrität ohne volles ACID¶
- Atomarität auf Dokumentebene: Operationen auf ein einzelnes Dokument sind meist atomar (alles oder nichts).
- Schema-Validierung: Einsatz von Validierungsregeln (z. B. JSON-Schema), um korrekte Datentypen und Pflichtfelder zu erzwingen.
- Applikationslogik: Die Integrität wird durch den Programmcode (Backend) sichergestellt, statt sich rein auf die Datenbank zu verlassen.
- Saga-Pattern: Komplexe Vorgänge werden in eine Kette von Einzelschritten mit entsprechenden Rückgängig-Aktionen (Compensating Transactions) aufgeteilt.
Frage 11: Rolle und Unterschiede von Indizes¶
- Rolle: Indizes dienen dazu, Abfragen zu beschleunigen, damit die Datenbank nicht jedes Dokument einzeln durchsuchen muss (Full Collection Scan).
- Unterschiede:
- Flexibilität: NoSQL-Indizes können auf tief verschachtelte Felder oder innerhalb von Listen (Arrays) liegen.
- Schema: SQL-Indizes basieren auf festen Spalten; NoSQL-Indizes können "spärlich" (Sparse) sein und nur Dokumente erfassen, die das Feld überhaupt enthalten.
- Verteilung: In NoSQL müssen Indizes oft über viele verteilte Server-Knoten (Shards) hinweg koordiniert werden.
Frage 12: Anwendungsfälle der NoSQL-Typen¶
- Key-Value (z. B. Redis): Schnelles Caching, Session-Management und Warenkörbe (hohe Geschwindigkeit, einfache Struktur).
- Document (z. B. MongoDB): Content-Management-Systeme (CMS), E-Commerce-Kataloge und Nutzerprofile (flexible Datenstrukturen).
- Column-Store (z. B. Cassandra): Big Data Analytics, Log-Auswertung und Zeitreihen-Daten (optimiert für massives Schreiben und Aggregieren).
- Graph (z. B. Neo4j): Soziale Netzwerke, Betrugserkennung und Empfehlungsdienste (Fokus auf komplexe Beziehungen zwischen Daten).
Einfache Fragen 03¶
Frage 1: Definition und Verwendung von NoSQL¶
- Definition: NoSQL steht für „Not Only SQL“. Es handelt sich um Datenbanken, die Daten nicht in klassischen, starren Tabellen speichern, sondern alternative Modelle nutzen (z. B. Dokumente oder Graphen).
- Verwendung: Sie werden für große Datenmengen (Big Data), Echtzeitanwendungen, Content-Management-Systeme und mobile Apps verwendet, bei denen sich die Datenstruktur häufig ändert oder sehr hohe Schreibgeschwindigkeiten nötig sind.
Frage 2: Drei Arten von NoSQL-Datenbanken¶
- Dokumentenorientiert (z. B. MongoDB): Speichert Daten in flexiblen Dokumenten (JSON/BSON). Jedes Dokument kann unterschiedliche Felder haben.
- Key-Value (z. B. Redis): Speichert Daten als einfache Schlüssel-Wert-Paare. Extrem schnell und ideal für Caching oder Sessions.
- Graphorientiert (z. B. Neo4j): Fokus liegt auf den Beziehungen zwischen Datenpunkten (Knoten und Kanten). Ideal für soziale Netzwerke oder Empfehlungssysteme.
Frage 3: Unterschied Relational vs. NoSQL¶
- Relational (SQL): Nutzt feste Tabellen mit vordefinierten Spalten. Änderungen am Schema sind aufwendig. Skaliert meist „vertikal“ (stärkerer Server).
- NoSQL: Nutzt flexible Strukturen (Dokumente, Graphen). Das Schema ist dynamisch und kann sich während des Betriebs ändern. Skaliert „horizontal“ (mehrere einfache Server im Verbund).
Frage 4: Vorteile von NoSQL-Datenbanken¶
- Flexibilität: Man muss sich nicht vorab auf ein festes Datenschema festlegen (Schema-on-read).
- Horizontale Skalierbarkeit: Einfaches Erweitern des Systems durch Hinzufügen günstiger Standard-Server.
- Performance: Schnelle Verarbeitung von unstrukturierten oder massiven Datenmengen, da keine komplexen Tabellen-Verknüpfungen (Joins) berechnet werden müssen.
- Agilität: Entwickler können schneller auf Änderungen in der Applikation reagieren, da die Datenbankstruktur mitwächst.
Mittlere Fragen 03¶
Frage 5: Dokumentenmodell in NoSQL¶
- Erklärung: In diesem Modell werden Daten in Dokumenten (meist im JSON- oder BSON-Format) gespeichert. Ein Dokument enthält alle relevanten Informationen zu einem Objekt als Set von Feld-Wert-Paaren. Dokumente sind flexibel, das heißt, verschiedene Dokumente in derselben Sammlung können unterschiedliche Felder haben.
- Beispiel: Ein Dokument für einen Benutzer in einer Datenbank:
Frage 6: Schlüssel-Wert- vs. dokumentenorientierte Datenbank¶
- Schlüssel-Wert (Key-Value): Die Datenbank sieht den Wert als "Blackbox" (einfache Zeichenfolge oder Binärdaten). Man kann nur über den Schlüssel suchen. (Einfach & extrem schnell).
- Dokumentenorientiert: Die Datenbank "versteht" die Struktur des Dokuments. Man kann gezielt nach Feldern innerhalb des Dokuments suchen (z. B. "Suche alle Nutzer, deren Interesse 'Klettern' ist"). (Komplexer & flexibler).
Frage 7: Rolle und Vorteile von Indizes¶
- Rolle: Ein Index ist eine Datenstruktur, die einen kleinen Teil der Daten (z. B. ein bestimmtes Feld) sortiert speichert, um Suchanfragen zu beschleunigen. Er fungiert wie ein Inhaltsverzeichnis in einem Buch.
- Vorteile:
- Geschwindigkeit: Abfragen finden Ergebnisse in Millisekunden, statt die gesamte Datenbank zu durchsuchen (Full Collection Scan).
- Effizienz: Reduziert die Last auf den Prozessor (CPU) und die Festplatte.
- Sortierung: Unterstützt das schnelle Sortieren von Ergebnissen.
Frage 8: Graphdatenbank und Anwendungsfälle¶
- Definition: Eine Graphdatenbank speichert Daten als Knoten (Entities) und Kanten (Beziehungen). Der Fokus liegt darauf, wie Datenpunkte miteinander verbunden sind, statt nur auf den Datenpunkten selbst.
- Anwendungsfälle:
- Soziale Netzwerke: Wer ist mit wem befreundet? (z. B. Facebook, LinkedIn).
- Empfehlungsdienste: Kunden, die Produkt A kauften, kauften auch B.
- Betrugserkennung: Analyse von Geldflüssen zwischen vielen Konten.
- Netzwerk-Mapping: IT-Infrastrukturen und deren Abhängigkeiten darstellen.
Schwere Fragen 03¶
Frage 9: Horizontale vs. vertikale Skalierung¶
- Vertikale Skalierung (Scale-Up): Ein einzelner Server wird durch stärkere Hardware (mehr CPU, RAM, SSD) aufgerüstet.
-
Nachteil: Es gibt eine physische Leistungsgrenze und die Kosten steigen überproportional.
-
Horizontale Skalierung (Scale-Out): Es werden weitere Server zu einem Verbund (Cluster) hinzugefügt.
- Konzept: Die Datenlast wird mittels Sharding auf viele günstige Standard-Server verteilt. Dies ist das Kernkonzept von NoSQL, um nahezu unbegrenztes Wachstum zu ermöglichen.
Frage 10: Herausforderungen der Datenkonsistenz¶
- Herausforderungen: In verteilten Systemen dauert es Zeit, bis eine Änderung alle Serverknoten erreicht. Das führt zu Eventual Consistency (Benutzer sehen kurzzeitig veraltete Daten).
- Lösungsansätze:
- Quorum-Lesen/Schreiben: Eine festgelegte Mehrheit von Knoten muss eine Operation bestätigen.
- Einstellbare Konsistenz: Entwickler wählen pro Abfrage zwischen „Strong Consistency“ (langsam, aber sicher) oder „Eventual Consistency“ (schnell).
- Konfliktlösung: Einsatz von Zeitstempeln (Last Write Wins) oder Vektor-Uhren, um bei widersprüchlichen Daten die richtige Version zu bestimmen.
Frage 11: Transaktionsmanagement (SQL vs. NoSQL)¶
- Relationale Datenbanken: Nutzen das ACID-Prinzip (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit). Transaktionen sind immer sicher und konsistent, was jedoch in verteilten Systemen die Performance bremst.
- NoSQL-Datenbanken: Nutzen oft das BASE-Prinzip (Basically Available, Soft state, Eventual consistency).
- Vorteile: Höhere Verfügbarkeit und Geschwindigkeit bei massiven Schreiblasten.
- Nachteile: Komplexe Transaktionen über mehrere Dokumente hinweg sind schwieriger zu realisieren (obwohl moderne NoSQL-Systeme wie MongoDB dies mittlerweile eingeschränkt unterstützen).
Frage 12: CAP-Theorem¶
Das CAP-Theorem besagt, dass ein verteiltes System nur zwei von drei Eigenschaften gleichzeitig garantieren kann:
- Consistency (Konsistenz): Alle Knoten liefern zu jedem Zeitpunkt dieselben Daten.
- Availability (Verfügbarkeit): Jede Anfrage wird beantwortet (auch wenn ein Knoten ausfällt).
- Partition Tolerance (Partitionstoleranz): Das System arbeitet weiter, selbst wenn die Kommunikation zwischen Knoten unterbrochen ist.
Bedeutung: Da Netzwerkfehler (P) in verteilten Systemen unvermeidlich sind, müssen NoSQL-Datenbanken sich entscheiden, ob sie im Fehlerfall lieber konsistent (CP) bleiben (und Anfragen ablehnen) oder verfügbar (AP) bleiben (und eventuell veraltete Daten liefern).
Einfache Fragen 04¶
Frage 1: Verbindung herstellen und moviesDB erstellen¶
In der MongoDB Shell (mongosh) wechselst du mit dem use-Befehl zur Datenbank. Sie wird physisch erstellt, sobald das erste Dokument gespeichert wird.
Frage 2: Filmdaten in die movies-Collection einfügen¶
Zum Einfügen eines Datensatzes nutzt du die Methode insertOne().
Frage 3: Eingefügte Daten in der movies-Collection prüfen¶
Mit der Methode find() kannst du dir alle Dokumente einer Collection anzeigen lassen.
Frage 4: Eine Auszeichnung in die awards-Collection einfügen¶
Hier wechselst du lediglich den Namen der Collection auf awards.
Mittlere Fragen 04¶
Frage 5: Verschachtelte Bewertungen hinzufügen¶
In MongoDB nutzt man eingebettete Dokumente (Sub-Documents), um hierarchische Strukturen abzubilden.
Befehl (Update eines bestehenden Films):
db.movies.updateOne(
{ title: "Inception" },
{ $set: { ratings: { imdb: 8.8, tomatometer: 87 } } }
)
Hinweis: Das Feld ratings enthält hier ein eigenes Objekt mit den Unterfeldern imdb und tomatometer.
Frage 6: Kommentare mit Benutzerinformationen hinzufügen¶
Kommentare werden meist als Array von Objekten gespeichert, damit mehrere Einträge möglich sind.
Befehl:
db.movies.updateOne(
{ title: "Inception" },
{ $push: {
comments: { user: "Lars", text: "Genialer Film!", date: new Date() }
}
}
)
Hinweis: $push fügt das neue Kommentar-Objekt dem Array comments hinzu.
Frage 7: Strukturprüfung eines JSON-Dokuments¶
Es gibt drei gängige Wege, um die Korrektheit (Syntax) zu prüfen:
- Online JSON Linter: Tools wie JSONLint prüfen auf fehlende Kommas, Anführungszeichen oder Klammern.
- MongoDB Shell/Compass: Beim Einfügen meldet die Datenbank sofort einen "Syntax Error", wenn die Struktur ungültig ist.
- Schema Validation: In MongoDB können Regeln hinterlegt werden (
$jsonSchema), die erzwingen, dass Dokumente bestimmten Datentypen oder Strukturen entsprechen müssen.
Frage 8: Abfrage basierend auf IMDb-Bewertungen¶
Um auf verschachtelte Felder zuzugreifen, nutzt man in MongoDB die Punktnotation (Dot Notation). Wichtig: Der Pfad muss in Anführungszeichen stehen.
Befehl:
Erklärung: Dieser Befehl findet alle Filme, deren IMDb-Bewertung größer als ($gt) 8.5 ist.
Schwere Fragen 04¶
Frage 9: Wiederherstellung mflix¶
- Tools: Installation der
mongodb-database-tools(enthältmongorestore). Auf dem Mac meist via Homebrew:brew install mongodb-database-tools. - Umgebungsvariable: Der Pfad zum
bin-Ordner der Tools muss in der Variable$PATH(in der Datei.zshrc) hinterlegt sein, damit der Befehl überall erkannt wird. - Befehl:
mongorestore --db mflix /pfad/zu/deiner/sicherung/mflix - Prüfung:
mongorestore --versionim Terminal eingeben. Erscheint die Version, ist alles korrekt eingerichtet.
Frage 10: Komplexe Abfrage (DiCaprio, Scorsese, Genres)¶
Hier nutzt du den find-Befehl mit mehreren Kriterien und einer Projektion (um nur Titel und Jahr anzuzeigen).
Befehl:
db.movies.find(
{
cast: "Leonardo DiCaprio",
directors: "Martin Scorsese",
genres: { $in: ["Drama", "Crime"] }
},
{ title: 1, year: 1, _id: 0 }
)
Frage 11: Anzahl und Details (Schauspieler vs. Regisseur)¶
-
Als Schauspieler (Details & Anzahl):
-
Als Regisseur (Anzahl):
Frage 12: Schemaanforderungen prüfen¶
- Prüfung des Schemas: Mit
db.getCollectionInfos({ name: "movies" })kannst du prüfen, ob für die Collection bereits ein$jsonSchemahinterlegt wurde. - Fehlerhafte Einträge finden: Falls Dokumente Pflichtfelder wie
title,yearodergenresnicht enthalten, findest du diese mit dem$exists-Operator:
Random sachen¶
Hier sind ein paar wichtige Konzepte, die oft in Tests abgefragt werden oder dir beim Arbeiten mit MongoDB auf dem Mac Zeit sparen:
1. Der Begriff "CRUD"¶
Das ist das Einmaleins jeder Datenbank. Es beschreibt die vier Grundfunktionen:
- Create: Daten erstellen (
insertOne) - Read: Daten lesen (
find) - Update: Daten ändern (
updateOne) - Delete: Daten löschen (
deleteOne)
2. Collection vs. Tabelle¶
Wenn du aus der SQL-Welt kommst, merk dir einfach:
- In SQL hast du eine Tabelle.
- In MongoDB heißt das Collection. Es ist im Grunde nur ein "Ordner", in dem deine Dokumente liegen.
3. Der Primary Key (_id)¶
Jedes Dokument in MongoDB bekommt automatisch ein Feld namens _id.
- Was es ist: Ein digitaler Fingerabdruck (eindeutiger Schlüssel).
- Warum: Damit die Datenbank jedes Dokument zweifelsfrei wiederfindet, selbst wenn zwei Filme den exakt gleichen Titel haben.
4. Vergleichs-Operatoren (Kürzel)¶
In der Shell nutzt du oft Kürzel für Abfragen. Die wichtigsten sind:
$gt(Greater Than): Größer als (>)$lt(Less Than): Kleiner als (<)$eq(Equal): Gleich (=)$ne(Not Equal): Ungleich (!=)$in: Schaut, ob ein Wert in einer Liste vorkommt (z.B. Genre "Drama" oder "Action").
5. JSON vs. BSON¶
- JSON: Das ist das Textformat, das du liest und schreibst (mit geschweiften Klammern
{}). - BSON: Das ist die "Binär-Version" davon. MongoDB speichert die Daten intern als BSON, weil der Computer das viel schneller verarbeiten kann als normalen Text.
6. Backup vs. Restore¶
Das sind zwei verschiedene Tools:
- mongodump: Erstellt eine Sicherung deiner Datenbank (macht ein "Foto" vom aktuellen Stand).
- mongorestore: Spielt diese Sicherung wieder ein (deine Aufgabe mit
sample_training).
7. Sharding vs. Replikation¶
- Replikation: Man kopiert die Daten auf mehrere Server. Wenn einer brennt, sind die Daten auf dem anderen noch da (Sicherheit).
- Sharding: Man zerteilt eine riesige Datenbank in kleine Stücke und verteilt sie auf viele Server (Geschwindigkeit bei riesigen Datenmengen).
8. Ein hilfreicher Mac-Befehl (Terminal)¶
Wenn du schnell wissen willst, wo deine MongoDB-Tools liegen, gib das ein:
Wenn ein Pfad wie /opt/homebrew/bin/mongorestore erscheint, ist alles perfekt eingestellt. Wenn nichts kommt, ist die Umgebungsvariable falsch.