Ganze_Theorie
Lernfeld 1: Theorie¶
1. Was ist eine "data-driven organization"?¶
Das ist ein Unternehmen, das Entscheidungen auf Basis von Daten trifft. Beispiel: Statt einfach ein neues Produkt zu erfinden, schaut man zuerst in den Daten, was die Kunden wirklich wollen.
2. Welche Vorteile hat das?¶
- Entscheidungen sind faktenbasiert, nicht nur aus Gefühl
- Man kann besser planen und vorhersagen
- Fehler fallen früher auf
- Man spart Zeit und Geld, weil man gezielter arbeitet
3. Beispiel für so ein Unternehmen¶
Netflix: Sie analysieren, was die Leute schauen – wann sie stoppen, weiterschauen usw. Dann produzieren sie gezielt Serien, die gut ankommen. So sparen sie Geld und bekommen viele Zuschauer.
4. Was machen Datenanalysten und Data Scientists?¶
| Rolle | Aufgabe |
|---|---|
| Datenanalyst | Sammelt und wertet Daten aus, z. B. für Berichte oder Diagramme |
| Data Scientist | Baut Programme, die mit den Daten z. B. Vorhersagen oder Empfehlungen machen |
5. Erklärung vom Lego-Diagramm¶

Das Bild mit Lego zeigt den Ablauf:
- Viele bunte Steine = Rohdaten
- Lastwagen bringt sie = Datenaufnahme
- Teile werden geordnet = Verarbeitung
- Haus entsteht = Entscheidung auf Basis von Daten
Es zeigt: Aus Chaos (Rohdaten) wird Struktur → man kann etwas draus machen.
6. Was sind die Elemente einer Data Pipeline?¶
Eine Data-Pipeline ist wie eine Datenstrasse. Schritt für Schritt:
- Daten sammeln (z. B. von Webseiten, Apps)
- Speichern (z. B. in S3 oder Redshift)
- Verarbeiten (z. B. aufräumen, umwandeln)
- Analysieren (z. B. mit SQL)
- Anzeigen (z. B. in Diagrammen)
- Entscheiden/automatisieren
Diagramm erklären:¶
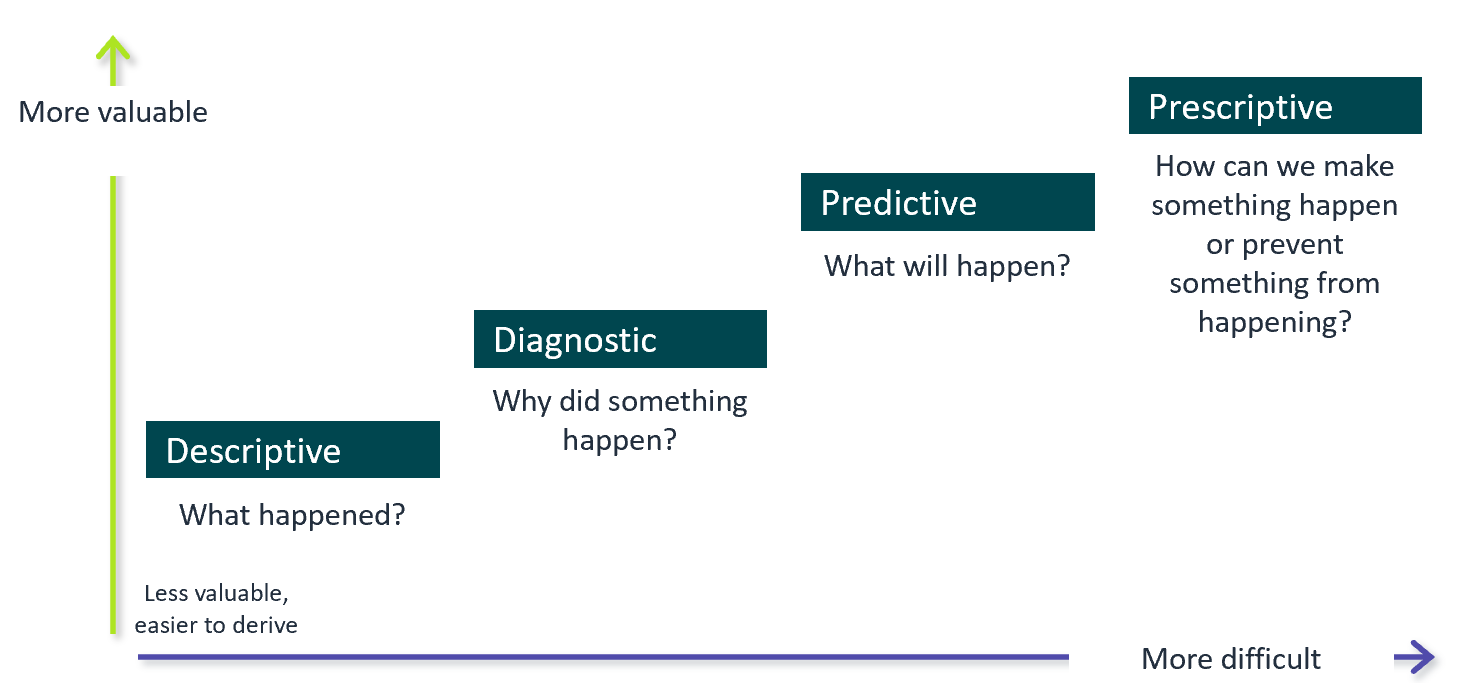
Das Diagramm zeigt, wie man Daten nutzen kann – von einfach bis komplex:
- Descriptive: Was ist passiert? (z. B. Anzahl Verkäufe letzte Woche)
- Diagnostic: Warum ist es passiert? (z. B. wegen Rabattaktion)
- Predictive: Was wird passieren? (z. B. nächste Woche steigen Verkäufe wieder)
- Prescriptive: Was sollen wir tun? (z. B. Werbung starten, um mehr Verkäufe zu bekommen)
Je weiter rechts, desto nützlicher, aber auch schwieriger.
Lernfeld 2: The Elements of Data (Modul 3)¶
Strukturierte, halbstrukturierte, unstrukturierte Daten:¶
- Strukturiert: In Tabellen, mit klaren Spalten (z. B. Excel, SQL-Datenbank)
- Halbstrukturiert: Hat Struktur, aber nicht fix (z. B. JSON, XML)
- Unstrukturiert: Keine feste Form (z. B. Bilder, Videos, Texte)
Die 5 V's im Datenbereich:¶
- Volume = Datenmenge
- Velocity = Geschwindigkeit der Entstehung
- Variety = Unterschiedliche Datenformate
- Veracity = Vertrauenswürdigkeit / Qualität
- Value = Nutzen der Daten
Was bedeuten sie?¶
- Volume: Wie viel Daten gibt es? (z. B. viele Log-Dateien, grosse Datenbanken)
- Velocity: Wie schnell kommen neue Daten? (z. B. Livestream, Sensoren)
- Variety: Welche Arten von Daten? (z. B. Video, Text, Zahl)
- Veracity: Sind die Daten korrekt? (z. B. falsch erfasst oder manipuliert?)
- Value: Was bringt mir das Ganze? (Nutzwert für die Firma)
Welches V ist am wichtigsten?¶
Value – denn am Ende zählt nur, ob die Daten einen Nutzen bringen. Viele Daten nützen nichts, wenn man sie nicht sinnvoll einsetzen kann.
Wie hängen Volumen & Geschwindigkeit zusammen?¶
Je mehr Daten (Volume) es gibt und je schneller (Velocity) sie ankommen, desto stärker wird das System belastet. Man braucht also gute Tools, um die Daten schnell zu verarbeiten – sonst gibt es Verzögerungen.
Beispiel Börse (Hochfrequenzhandel):¶
Hier kommen sehr viele Daten pro Sekunde (hohes Volume) und sie müssen sofort verarbeitet werden (hohe Velocity). Das ist extrem fordernd und braucht Echtzeitverarbeitung.
Einschätzung für die Börse:¶
- Value: Sehr hoch – jede Millisekunde entscheidet über Gewinn oder Verlust
- Veracity: Muss hoch sein – Fehlerhafte Daten → falsche Entscheidungen
- Variety: Eher niedrig – es sind meist strukturierte Zahlen (z. B. Kurse, Zeitstempel)
Lernfeld 3: Design Principles and Patterns for Data Pipelines¶
Wie vereinheitlicht AWS verschiedene Datenquellen?¶
AWS speichert alle Daten – egal ob strukturiert oder unstrukturiert – in einem zentralen Speicher, z. B. Amazon S3. Dann können Tools wie Athena, Glue, Redshift, SageMaker auf die gleichen Daten zugreifen. Das macht eine einheitliche Sicht auf die Daten möglich – egal woher sie kommen.
Aufbau einer modernen Datenarchitektur (siehe Diagramm):¶
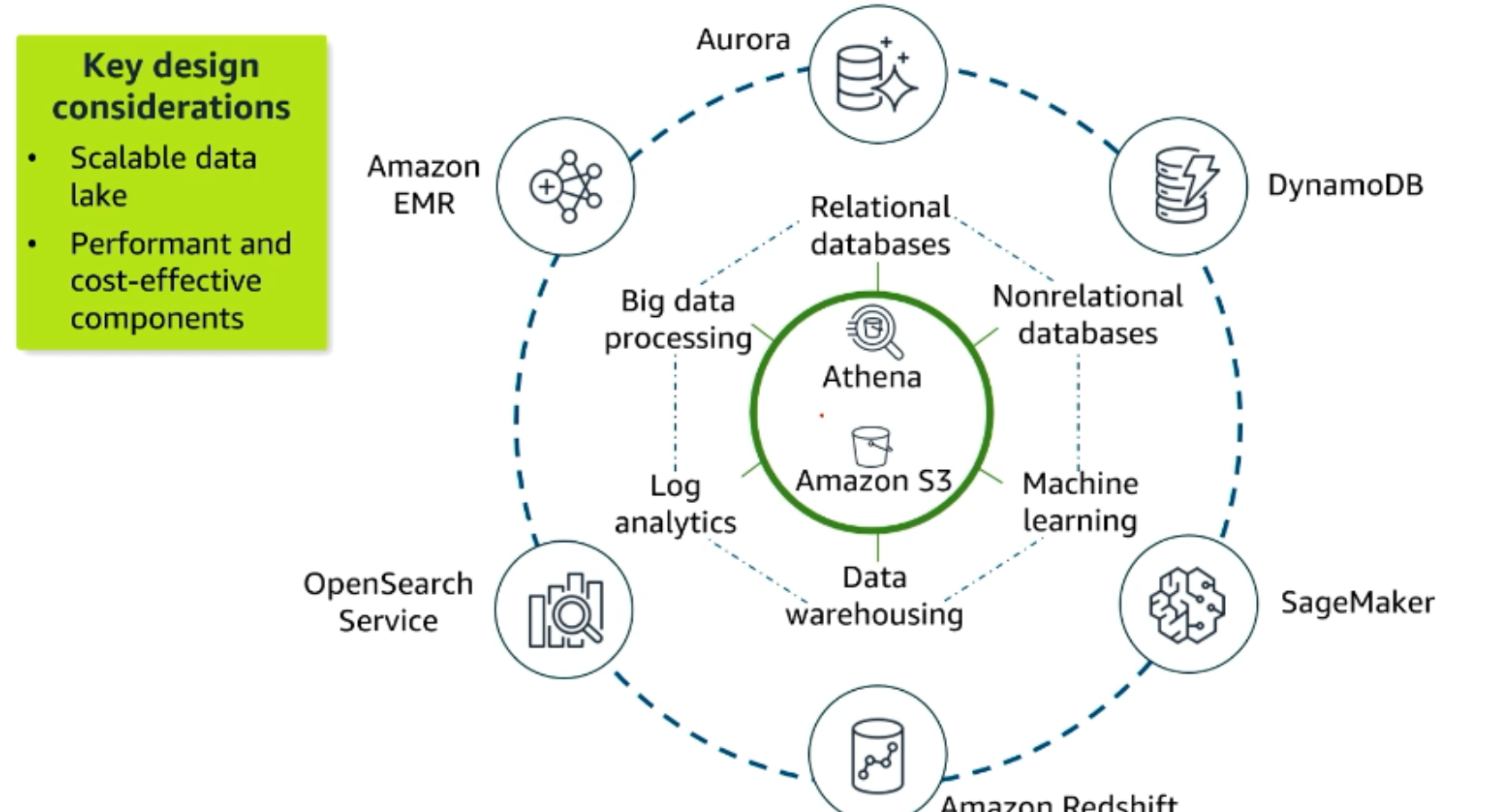
- Amazon S3 ist die zentrale Speicherstelle (Data Lake).
- Athena greift direkt auf die Daten zu (für SQL-Abfragen).
- Andere Dienste wie Redshift (Data Warehouse), EMR (Big Data) oder SageMaker (ML) greifen ebenfalls auf diese Daten zu.
- Ziel: Skalierbar, günstig, leistungsfähig
In welchen Ebenen passiert was?¶
- Nutzungsebene → SQL-Abfragen (z. B. mit Athena)
- Verarbeitungsebene → Big-Data-Verarbeitung (z. B. mit EMR oder Glue)
Was ist eine Streaming-Analytics-Pipeline?¶
Daten kommen laufend (z. B. aus Sensoren, Börse).
- Produzenten senden die Daten (z. B. ein Gerät oder Server)
- Konsumenten lesen & analysieren die Daten (z. B. AWS Kinesis, Lambda)
Beispielworkflow: Athena + Glue¶
- Daten liegen in S3
- Glue-Datenkatalog beschreibt die Struktur (Tabelleninfos)
- Athena nutzt diesen Katalog und führt SQL-Abfragen auf den Daten aus
AWS Glue¶
= Aufräumer
- Holt Daten, erkennt Spalten, macht sie bereit
- Merkt sich, wie die Daten aussehen (= Glue-Katalog)
Amazon Athena¶
= Frager
- Du stellst Fragen an die Daten mit SQL
- Antwortet direkt auf Daten, die in S3 liegen
Glue bereitet vor – Athena fragt ab. Beides braucht man oft zusammen.
QAY<§sawq
Begriffserklärung:¶
- SQL: Sprache zum Abfragen von Daten
- DDL: Data Definition Language (z. B. CREATE TABLE)
- DML: Data Manipulation Language (z. B. SELECT, INSERT)
Datenherkunft bei CREATE EXTERNAL TABLE¶
Die Daten werden nicht in die Tabelle geladen, sondern liegen extern in S3 (LOCATION ...).
Mit ROW FORMAT SERDE wird gesagt, wie die Daten gelesen werden (z. B. Trennzeichen).
Erklärung SQL-SELECT (Bild 3)¶
→ Zeigt: Wie viele Fahrten und wie viel Geld pro Tag im Januar 2017.
Wird gruppiert nach Datum (GROUP BY pickup)
Erklärung SELECT sum(total), paytype ...¶
→ Rechnet Gesamtumsatz für paytype = '1' Wird gruppiert nach Zahlungsart
Erklärung CREATE VIEW¶
→ Erstellt eine sichtbare Abfrage (View), die immer den Gesamtbetrag aller Kreditkartenzahlungen zeigt. Vorteil: Muss nicht immer neu geschrieben werden
Was macht SELECT * FROM cctrips?¶
→ Holt die gespeicherten Daten aus der View – zeigt alle Zeilen der View cctrips.
Erklärung AWS Template (Named Query)¶
AWSTemplateFormatVersion: 2010-09-09
Resources:
AthenaNamedQuery:
Type: AWS::Athena::NamedQuery
Properties:
Database: "taxidata"
Name: "FaresOver100DollarsUS"
QueryString: >
SELECT ... WHERE total >= 100.0
→ Speichert eine SQL-Abfrage dauerhaft in Athena, um alle Fahrten mit Preis über 100 Dollar zu analysieren.
Lernfeld 4: Securing and Scaling (M5)¶
1. Zwei Massnahmen bei verdächtigen Aktivitäten:¶
- CloudTrail aktivieren → zeichnet alle API-Zugriffe auf
- IAM-Rollen einschränken → nur das Nötigste erlauben (Least Privilege)
2. Skalierbarkeit der Datenpipeline sicherstellen:¶
- Auto Scaling aktivieren (z. B. bei Kinesis oder Glue)
- Serverless-Dienste wie Athena, Glue, Lambda nutzen → skalieren automatisch
Ingesting and Preparing Data (M6)¶
3. Was ist ein ETL-Dienst wie AWS Glue?¶
→ Daten werden gesammelt (Extract), umgewandelt (Transformiert) und gespeichert (Load) Glue hilft dabei automatisch → ohne eigenen Server
4. Vorteile ETL statt ELT:¶
- Daten werden vor dem Speichern aufgeräumt
- Spart Speicherplatz
- Nur saubere Daten kommen ins Ziel
5. Vorteile ELT statt ETL:¶
- Rohdaten bleiben erhalten (für spätere Nutzung)
- Rechenlast ist im Zielsystem
- Flexibler bei späteren Änderungen
Okay – hier ganz genau erklärt, was ETL und ELT sind:
ETL = Extract – Transform – Load¶
1. Extract = Daten werden geholt → z. B. aus Excel, Datenbanken, CSV-Dateien
2. Transform = Daten werden bearbeitet / umgewandelt → z. B. Spalten umbenennen, Werte berechnen, Fehler korrigieren
3. Load = Fertige Daten werden gespeichert → z. B. in Amazon Redshift oder S3
Verarbeitung passiert vor dem Speichern
ELT = Extract – Load – Transform¶
1. Extract = Daten holen 2. Load = Daten sofort ungereinigt speichern 3. Transform = Daten werden danach im Zielsystem aufbereitet
Verarbeitung passiert erst nach dem Speichern
Unterschied:
| ETL | ELT | |
|---|---|---|
| Aufräumen | Vor dem Speichern | Nach dem Speichern |
| Speicher | Nur saubere Daten | Auch Rohdaten bleiben |
| Rechenlast | Im ETL-Tool (z. B. Glue) | Im Zielsystem (z. B. Redshift) |
| Flexibilität | Weniger, aber schneller | Mehr, aber braucht mehr Power |
Beispiel AWS Glue: → Glue kann ETL automatisch machen (also alles aufräumen und dann speichern)
6. Was ist Data Wrangling?¶
→ Daten zusammenführen, bereinigen und umwandeln – vor allem wenn sie aus verschiedenen Quellen kommen (z. B. Excel, JSON, SQL)
7. Schritte im Data Wrangling:¶
- Cleaning → Fehler entfernen
- Structuring → gleiche Struktur machen
- Enriching → neue Infos hinzufügen
- Validating → prüfen, ob alles korrekt ist
Ingesting by Batch or Stream (M7)¶
8. Unterschied Batch vs Stream:¶
| Batch | Stream |
|---|---|
| Daten werden gesammelt | Daten kommen sofort |
| Verarbeitung nach Plan | Echtzeitverarbeitung |
| z. B. Tagesbericht | z. B. Live-Aktienkurs |
9. Wann welche Methode?¶
- Batch: ideal bei statischen Daten (Berichte, Backups)
- Stream: ideal bei Live-Daten (Sensoren, Börse, Klicks)
Lernfeld 5: Storing and Organizing (M8)¶
1. Zwei weitere Speicherlösungen neben S3:¶
- Amazon RDS: Relationale Datenbank (z. B. MySQL, PostgreSQL) → für strukturierte Daten
- Amazon DynamoDB: NoSQL-Datenbank → für sehr schnelle, flexible Datenzugriffe (z. B. Userprofile)
2. Unterschied Data Lake vs. Data Warehouse:¶
| Merkmal | Data Lake | Data Warehouse |
|---|---|---|
| Datentyp | Rohdaten (alle Formate) | Nur strukturierte Daten |
| Flexibilität | Sehr flexibel | Strenger Aufbau |
| Kosten | Günstiger | Teurer |
| Zugriff | Später verarbeitet | Für schnelle Analyse gedacht |
3. Anwendungsfälle:¶
- Data Lake: Wenn viele verschiedene Formate vorliegen, z. B. Bilder, Videos, JSON (z. B. Social Media Archiv)
- Data Warehouse: Wenn schnelle Analysen nötig sind, z. B. BI-Berichte für Verkaufszahlen
4. Kriterien für die optimale Datenbank:¶
(Bild oben hilft – rote Balken stehen für Kategorien)
- Workload type: Transaktionen oder Analysen?
- Data model: Wie oft & wie wird zugegriffen?
- Performance: Muss es schnell sein?
- Operational needs: Sicherheit, Backups, Updates?
5. Weitere DB-Art + Beispiel:¶
- DocumentDB / MongoDB (NoSQL) → z. B. für Produktkataloge in Online-Shops mit variabler Struktur
6. Redshift: getrennte Sicherheit¶
- Service-Sicherheit: Wer darf Redshift überhaupt benutzen (z. B. über IAM)
- Datenbanksicherheit: Wer darf welche Tabellen/Spalten sehen oder ändern
Processing Big Data (M9)¶
7. Was ist Big Data + 2 Beispiele:¶
→ Sehr grosse, schnelle oder vielfältige Datenmengen Beispiele:
- Verkehrsdaten von GPS-Geräten
- Klickverhalten von Millionen Webseitenbesuchern
8. Batch vs. Streaming (bei Big Data):¶
| Methode | Vorteil | Nachteil |
|---|---|---|
| Batch | Einfach, effizient | Nicht in Echtzeit |
| Streaming | Echtzeitanalyse möglich | Komplexer, teurer |
9. Herausforderungen bei Big Data:¶
- Speicherung grosser Mengen
- Echtzeitverarbeitung bei hohem Tempo
- Datenqualität prüfen
- Sicherheit & Zugriff korrekt steuern
Lernfeld 6: Processing Data for Machine Learning (M10)¶
1. Wie automatisiert man den Datenverarbeitungsprozess?¶
→ Mit Pipelines: Abläufe wie Daten bereinigen → umwandeln → trainieren → testen werden automatisch Schritt für Schritt ausgeführt. Tools: z. B. AWS SageMaker Pipelines
2. Was ist Data-Splitting?¶
→ Aufteilen der Daten in:
- Training Set: Modell lernt damit
- Test Set: Modell wird geprüft (meist z. B. 80 % Training, 20 % Test)
So vermeidet man, dass das Modell „auswendig lernt“.
3. Was tun bei unbalancierten oder unvollständigen Daten?¶
-
Unbalanciert (z. B. 95 % Nein, 5 % Ja):
-
Mehr Daten vom seltenen Fall sammeln
-
Gewichtung anpassen oder Sampling nutzen
-
Unvollständig:
-
Fehlende Werte auffüllen (z. B. Durchschnitt)
- Oder: Zeilen mit fehlenden Daten weglassen (wenn wenige)