Alle_Theorie_bis_jetzt
SQL vs NoSQL¶
| Begriff | Bedeutung |
|---|---|
| SQL | Structured Query Language – Standardisierte Sprache für relationale Datenbanken. |
| NoSQL | Not Only SQL – Datenbanken mit flexiblen Strukturen, die nicht ausschliesslich auf SQL basieren. |
| Aspekt | SQL-Datenbanken (Relational) | NoSQL-Datenbanken |
|---|---|---|
| Datenmodell | Relational (Tabellen mit Zeilen und Spalten) | Nicht-relational (z. B. Dokumente, Schlüssel-Wert, Graphen) |
| Schema | Festes Schema, Änderungen erfordern Migration | Flexibles Schema, keine festen Strukturen notwendig |
| Skalierung | Vertikale Skalierung (Leistungssteigerung durch grössere Server) | Horizontale Skalierung (Verteilung auf viele Server) |
| Abfragesprache | SQL (standardisierte Abfragesprache) | Keine feste Sprache, oft API- oder spezialisierte Queries |
| Konsistenz | Stark konsistent | Eventuell eventual consistency (abhängig vom Modell) |
| Anwendungsfälle | Geeignet für strukturierte Daten und Transaktionen | Geeignet für grosse Datenmengen, unstrukturierte Daten |
| Beispiele | MySQL, PostgreSQL, Oracle Database | MongoDB, Cassandra, Redis, Neo4j |
| Transaktionen | Unterstützt ACID-Transaktionen (atomicity, consistency, isolation, durability) | Oft BASE-Prinzip (basic availability, soft state, eventual consistency) |
SQL-Datenbanken sind ideal für klare, strukturierte Daten mit festen Beziehungen, während NoSQL-Datenbanken für flexible und skalierbare Anwendungen geeignet sind.
ACID¶
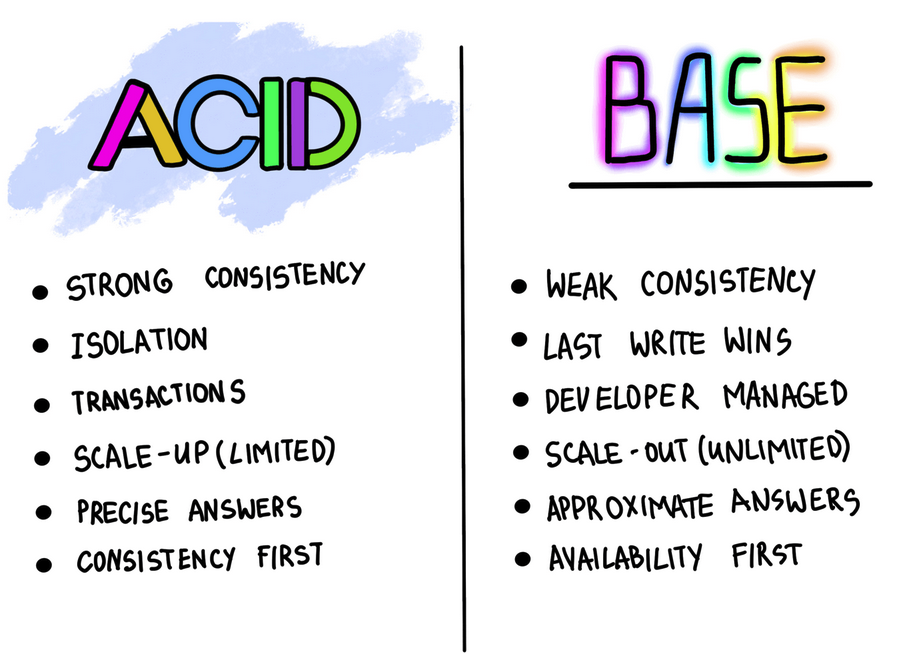

ACID erklärt¶
Einfache Übersicht zu ACID:
| Buchstabe | Bedeutung | Beschreibung |
|---|---|---|
| A | Atomicity (Atomarität) | Eine Transaktion wird entweder vollständig durchgeführt oder gar nicht. |
| C | Consistency (Konsistenz) | Der Datenbestand bleibt vor und nach der Transaktion gültig und konsistent. |
| I | Isolation (Isolation) | Transaktionen beeinflussen sich nicht gegenseitig, auch wenn sie gleichzeitig laufen. |
| D | Durability (Dauerhaftigkeit) | Erfolgreich abgeschlossene Transaktionen bleiben dauerhaft gespeichert. |
ACID wird vor allem bei SQL-Datenbanken verwendet, um sichere und zuverlässige Transaktionen zu gewährleisten.
MongoDB erkärt¶
MongoDB ist eine NoSQL-Datenbank, die Daten in JSON-ähnlichen Dokumenten speichert. Es ist flexibel, da kein festes Schema nötig ist, und eignet sich besonders für unstrukturierte oder sich ändernde Daten.
Hauptmerkmale:¶
- Dokumentbasierte Speicherung: Daten werden in Collections (ähnlich wie Tabellen) organisiert, und jedes Dokument (ähnlich wie eine Zeile) hat ein flexibles Format.
- Schemafrei: Kein festes Schema, daher einfach anpassbar.
- Horizontale Skalierbarkeit: Gut für grosse Datenmengen, da Daten auf mehrere Server verteilt werden können.
- Leicht verständlich: Verwendet ein Format, das JSON ähnelt, also leicht zu lesen und schreiben.
Anwendungsfälle:¶
- Echtzeit-Apps (z. B. Chat-Systeme)
- Content-Management-Systeme
- Grosse Datenmengen mit unregelmässigen Strukturen
MongoDB ist ideal, wenn du Flexibilität, Geschwindigkeit und Skalierbarkeit benötigst!
SQL vs No SQL beispiele:¶
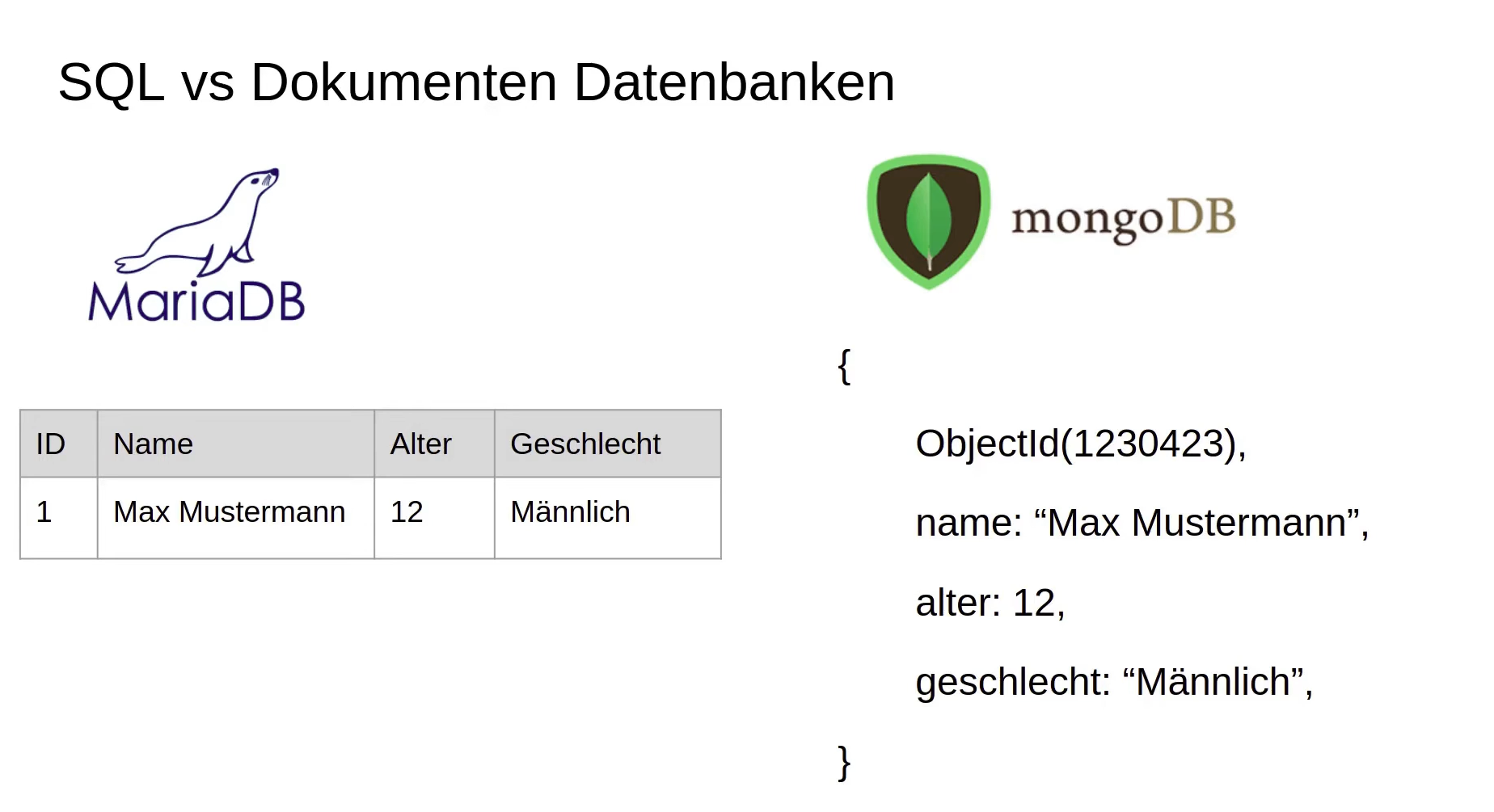



Berechtigungen IT-Administrator¶
Rolle und Berechtigungen des IT-Administrators¶
| Aufgabe | Beschreibung |
|---|---|
| Benutzerverwaltung | Erstellung und Verwaltung von Konten und Rollen. |
| Zugriffsrechte | Steuerung, wer auf welche Daten zugreifen darf. |
| Sicherheit | Schutz der Daten vor unautorisiertem Zugriff. |
| Wartung | Durchführung von Backups und Updates. |
| Fehlerbehebung | Behebung von Problemen in der Datenbank. |
Der IT-Administrator gewährleistet Sicherheit, Effizienz und korrekten Zugriff auf die Filmdatenbank.
Abstraktion¶
Abstraktion in SQL und NoSQL¶
| Aspekt | Beschreibung |
|---|---|
| Definition | Abstraktion vereinfacht Systeme, indem sie nur wichtige Details zeigt und andere verbirgt. |
| In SQL | - Tabellen zeigen die Datenstruktur einfach. - SQL-Nutzer müssen Speicherungsdetails nicht kennen. |
| In NoSQL | - Daten werden als Dokumente, Schlüssel-Wert-Paare oder Graphen gespeichert. - Skalierung und Verteilung sind verborgen. |
| Vorteile | - Einfacher Datenzugriff. - Weniger technische Details für Entwickler und Nutzer. |
Abstraktion macht Datenbanken leichter verständlich und nutzbar.
CAP-Theorem¶
Das CAP-Theorem besagt, dass verteilte Systeme immer nur 2 von 3 Eigenschaften gleichzeitig garantieren können:
| Eigenschaft | Beschreibung |
|---|---|
| Konsistenz (C) | Alle Knoten haben den gleichen Datenstand, Änderungen sind sofort sichtbar. |
| Verfügbarkeit (A) | Jede Anfrage wird beantwortet, auch bei Teilausfällen des Systems. |
| Partitionstoleranz (P) | Das System bleibt trotz Netzwerkausfällen zwischen Knoten funktionsfähig. |
| Typ | Eigenschaften | Beschreibung |
|---|---|---|
| CP | Konsistenz + Partitionstoleranz | Garantiert konsistente Daten trotz Netzwerkpartitionen, jedoch auf Kosten der Verfügbarkeit. (z. B. Banktransaktionen) |
| AP | Verfügbarkeit + Partitionstoleranz | Daten bleiben verfügbar trotz Netzwerkpartitionen, jedoch kann es zu inkonsistenten Daten kommen.(z. B. Social-Media-Posts) |
| CA | Konsistenz + Verfügbarkeit | Daten sind konsistent und verfügbar, funktioniert jedoch nicht bei Partitionstoleranz (nur in nicht-verteilten Systemen möglich)z. B. auf einem Gerät. |
In verteilten Datenbanken ist Partitionstoleranz (P) unverzichtbar, daher wählen sie zwischen CP oder AP je nach Anwendungsfall.
Wiso nicht alle 3 ?¶
Man kann nicht alle 3 (Konsistenz, Verfügbarkeit, Partitionstoleranz) gleichzeitig garantieren, weil bei Netzwerkausfällen (Partitionen) das System entweder:
- Konsistenz wählt (Daten korrekt, aber unzugänglich), oder
- Verfügbarkeit wählt (Daten erreichbar, aber evtl. inkonsistent).
Partitionstoleranz ist in verteilten Systemen unverzichtbar, daher muss man zwischen C und A entscheiden.
Netzwerkpartitionen¶
| Begriff | Beschreibung |
|---|---|
| Netzwerkpartitionen | Treten auf, wenn Knoten aufgrund von Netzwerkausfällen nicht mehr kommunizieren können. |
| Auswirkung | Systeme müssen sich entscheiden: Konsistenz oder Verfügbarkeit priorisieren. |
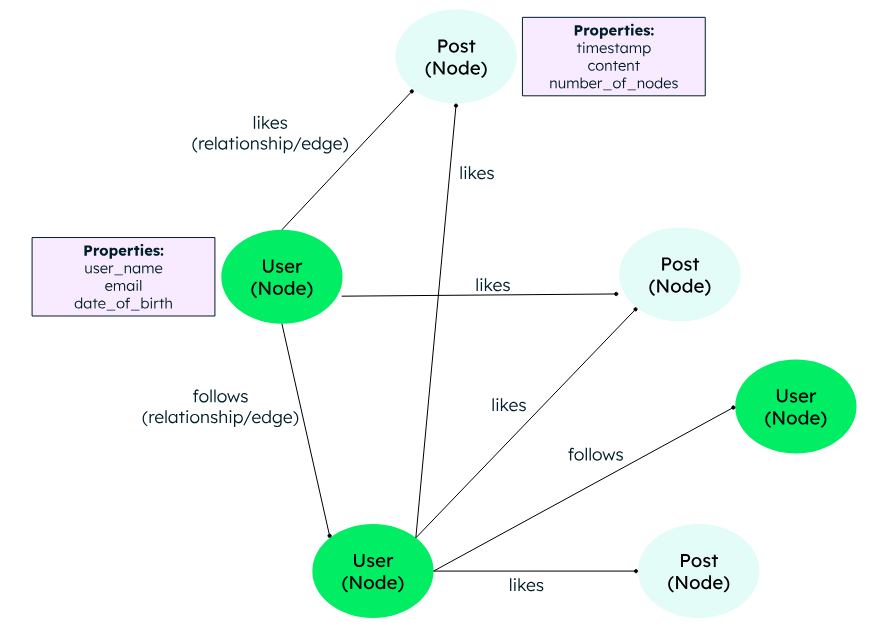
Graphdatenbanken¶
Was ist eine Graphdatenbank?¶
Eine Graphdatenbank speichert Daten als Knoten (Entities) und Kanten (Beziehungen) in einem Graphen-Modell.
- Knoten repräsentieren Objekte, z. B. Personen oder Produkte.
- Kanten zeigen die Beziehungen zwischen den Objekten, z. B. "kennt", "kauft", "gehört zu".
- Eigenschaften können Knoten und Kanten zusätzliche Informationen hinzufügen.
Beispiel: Neo4j, ArangoDB, OrientDB.
Anwendungsfälle von Graphdatenbanken¶
| Anwendungsfall | Einsatzbeispiel |
|---|---|
| Soziale Netzwerke | Darstellung von Freundschaften und Interaktionen, z. B. bei Facebook oder LinkedIn. |
| Empfehlungssysteme | Analyse von Beziehungen zwischen Nutzern und Produkten, z. B. Netflix, Amazon. |
| Betrugserkennung | Identifizierung verdächtiger Muster in Netzwerken, z. B. bei Banken. |
| Logistik und Routenplanung | Optimierung von Lieferketten oder kürzesten Wegen, z. B. bei Versanddienstleistern. |
| Wissensgraphen | Darstellung komplexer Wissensnetze, z. B. Google Knowledge Graph. |
Graphdatenbanken sind besonders nützlich, wenn Daten stark vernetzt sind und Beziehungen im Fokus stehen.
Beispiel:¶
Normalisierung und Denormalisierung¶
-
Normalisierung:
Daten werden in mehrere Tabellen aufgeteilt, um Redundanzen zu vermeiden und Datenintegrität zu gewährleisten. Beispiel: 3. Normalform stellt sicher, dass jede Tabelle nur von ihrem Primärschlüssel abhängt. -
Denormalisierung:
Daten werden absichtlich in einer weniger strikten Form gespeichert (z. B. mit Redundanzen), um schnelleren Zugriff zu ermöglichen. Statt Daten in mehreren Tabellen zu verteilen, werden sie oft in einem einzigen Dokument oder Datensatz zusammengefasst.
Unterschied:¶
- Normalisierung: Ideal für SQL-Datenbanken (klare Struktur, Integrität).
- Denormalisierung: Typisch in NoSQL-Datenbanken (schnellere Abfragen, flexible Datenmodelle).
Vor- und Nachteile der Denormalisierung in NoSQL-Datenbanken¶
| Aspekt | Vorteile | Nachteile |
|---|---|---|
| Performance | Schnellerer Datenzugriff, da weniger Abfragen nötig sind. | Kann zu redundanten Daten und höherem Speicherverbrauch führen. |
| Komplexität | Einfachere Abfragen durch zusammengefasste Daten. | Änderungen erfordern Anpassungen an mehreren Stellen. |
| Skalierung | Gut für verteilte Systeme mit schnellem Zugriff. | Schwerer bei vielen verknüpften Daten und häufigen Änderungen. |
Fazit¶
Denormalisierung erhöht die Performance, kann aber Redundanz und Konsistenzprobleme verursachen. Ideal, wenn Geschwindigkeit wichtiger als Datenintegrität ist.
Verschiedene DBs und Arten von No-SQL¶
| Art | Hauptmerkmale | Beispiele |
|---|---|---|
| Dokumentenbasiert | Daten in JSON-ähnlichen Dokumenten, flexibel. | MongoDB, CouchDB |
| Schlüssel-Wert | Einfache Speicherung als Schlüssel-Wert-Paare, extrem schnell. | Redis, DynamoDB |
| Spaltenorientiert | Speichert Daten spaltenweise, gut für grosse Datenanalysen. | Cassandra, HBase |
| Graphenbasiert | Modelliert Datenbeziehungen als Knoten und Kanten. | Neo4j, ArangoDB |
| Zeitserienbasiert | Speziell für zeitgestempelte Daten wie Logdaten oder Sensoren. | InfluxDB, TimescaleDB |
Die Art beschreibt den Ansatz, während die genannten Beispiele spezifische Implementierungen sind.
Datenkonsistenz in verteilten Systemen¶
Herausforderungen:¶
- Netzwerkausfälle: Daten können vorübergehend inkonsistent sein.
- Replikation: Verzögerte Synchronisation zwischen Knoten.
- Gleichzeitige Zugriffe: Konflikte bei gleichzeitigen Änderungen.
Lösungen:¶
- CAP enscheiden
Movies DB etc.¶
Erklärung des Codes:¶
- Verbindung zur MongoDB herstellen:
-
Stellt eine Verbindung zur MongoDB-Instanz her, die auf localhost (Standard: Port 27017) läuft.
-
Datenbank auswählen:
-
Wählt die Datenbank mflix_labs. Wenn sie nicht existiert, wird sie bei der ersten Verwendung erstellt.
-
Collection auswählen:
- Greift auf die Collection movies innerhalb der Datenbank mflix_labs zu. Wird automatisch erstellt, wenn ein Dokument hinzugefügt wird.
Verschachtelungen & JSON¶
Verschachtelte Bewertungen hinzufügen¶
Bewertungen können als eingebettete Daten in einem Dokument gespeichert werden, z. B.:
{
"title": "Beispiel",
"year": 2021,
"ratings": {
"Quelle1 (zb IMDB)": 9.2,
"Quelle2 (zb Tomatometer)": 50
}
}
¶
{
"title": "Beispiel",
"year": 2021,
"ratings": {
"Quelle1 (zb IMDB)": 9.2,
"Quelle2 (zb Tomatometer)": 50
}
}
Überprüfung von Dokumenten und fehlerhaften Einträgen (zb. in MongoDB)¶
-
Prüfen auf fehlende Felder:
Eine Abfrage kann genutzt werden, um Dokumente ohne bestimmte Felder (z. B.title,year,genres) zu finden: -
Fehlerhafte Einträge anzeigen:
Dokumente, bei denen die Felder fehlen, werden ausgegeben. So können sie leicht überprüft und korrigiert werden.
In MongoDB wird mit "$exists": False geprüft, ob ein bestimmtes Feld nicht vorhanden ist.
Erklärung:¶
$exists: True: Das Feld existiert im Dokument.$exists: False: Das Feld fehlt im Dokument.
Beispiel:¶
- Findet alle Dokumente, bei denen das Feldtitle fehlt.- Praktisch, um fehlerhafte oder unvollständige Einträge zu identifizieren.
Das hilft, fehlerhafte Daten schnell zu finden.
Rollen und Berechtigungen in der Datenbankverwaltung (GYM-Beispiel)¶
| Rolle | Berechtigungen |
|---|---|
| Administrator | Vollzugriff: Benutzer erstellen, Rechte verwalten. |
| Trainer | Zugriff auf Mitgliedsdaten und Trainingspläne, keine Zahlungsdaten. |
| Mitglied | Zugriff nur auf eigene Daten, z. B. Trainingspläne. sonst nichts |
Das Rollenspiel verdeutlicht, wie klare Berechtigungen Daten schützen und Fehlzugriffe verhindern.